In diesem Beitrag zeige ich im Detail den Zusammenhang zwischen einem Datenmodell in Quellcode und einer Datenmodellierung mit Hilfe von UML-Klassendiagrammen.
Was ist ein Datenmodell?
Eine Softwareanwendung hat eigentlich so gut wie immer die Aufgabe Daten zu verarbeiten. Verarbeiten heißt in dem Fall meist Daten zu verändern oder aus bestehenden Daten neue Daten zu erzeugen. In Rechnern kann man ausschließlich Daten speichern und diese verarbeiten. Datenmodelle bestehen aus einer Reihe so genannter Datentypen, die in einer bestimmten Art und Weise aufgebaut sind. In der Objektorientierung ist ein Datentyp durch ein Klasse definiert und die Begriffe Datenmodellklasse und Datentyp werden oftmals synonym verwendet.
Datentypen sind oftmals zusammengesetzt entweder aus anderen Datentypen. Dabei unterscheidet man zwischen so genannten primitiven Datentypen wie Zahlen mit oder ohne Kommastellen, einzelnen Textzeichen, längeren zusammenhängenden Texten (Zeichenketten, engl. String) oder dem so genannten Wahrheitswert (bool´scher Wert) mit der Aussage wahr oder falsch, oder anderen zusammengesetzten Datentypen, den so genannten komplexen Datentypen.
Man kann sich das so vorstellen wie ein Molekül, das aus Atomen besteht. Ein Molekül setzt sich aus Atomen zusammen, aber Atome sind die kleinste Einheit und können nicht so ohne weiters weiter zerlegt werden.
Genauso verhält es sich mit den Datentypen. Primitive Datentypen sind quasi die Atome. Die zusammengesetzten Datentypen sind die komplexen Datentypen.
Aus den Primitiven Daten kann man also durch Kombination dieser, einen komplexen Datentyp zusammensetzen. So wird zum Beispiel eine Person datentechnisch über die Daten „Vorname“ und „Name“ definiert. Diese beiden Daten sind wiederum über primitive Daten einer Zeichenkette (Strings) definiert.
Neben primitiven Datentypen können sich Daten auch aus weiteren komplexen Daten zusammensetzen. Wir werden später sehen, wie so etwas funktioniert.
Digitalisieren heißt immer die Welt in Daten abbilden
Da Daten das Einzige sind, was Computer und deren Software verarbeiten können, hat man es im Rahmen einer Digitalisierung immer damit zu tun, Dinge aus der realen Welt in bestimmte Datenmodelle zu bringen. Man kann eben keine materiellen Dinge im Computer speichern und verarbeiten, sondern nur Daten, die diese materiellen Dinge beschreiben.
In der Objektorientierung bildet man Objekte im Computer nach
Im Rahmen der objektorientierten Programmierung hat man dieses Prinzip der Abbildung von realen Objekten als Daten in Grundprinzipien übernommen, wie man Software für Computer entwickelt. Mit Hilfe von Objektorientierung kann man im Computer so genannte „Objekte“ erzeugen, die ein datentechnisches Abbild von Dingen aus der realen Welt sind. Dabei hat sich gezeigt, dass man oftmals mehr als ein Objekt gleicher „Art“ benötigt. Beispielsweise verwaltet eine Adressverwaltung eine Sammlung von Personenobjekten. Jede Person hat dann zwar unterschiedliche konkrete Daten für zum Beispiel Name und Vorname, jedoch hat jedes Personen-Objekt immer einen Namen und Vornamen. Das heißt, die Art eines Personenobjekts bleibt gleich, die konkreten Daten unterscheiden sich aber.
Mit Hilfe der (Software-)Modellierungssprache UML lassen sich solche Zusammenhänge der Objektorientierung auch grafisch darstellen. Abbildung 1 zeigt ein Beispiel für zwei Objekte von der Art – man sagt auch vom Typ – Person mit verschiedenen Daten.
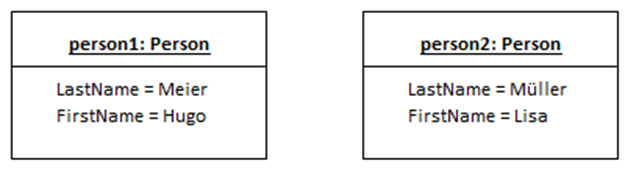
Die beiden Objekte beschreiben die Personen „Lisa Müller“ und „Hugo Meier“. Man sieht aber, dass die Art der Objekte, man könnte auch sagen die Struktur der Objekte, gleich ist. Beide Personen haben die Eigenschaften „LastName“ und „FirstName“, die man nun mit einem bestimmten Wert versehen kann.
Klassen sind der Bauplan eines Objektes
Wenn man nun Objekte gleicher Art hat, dann sollte es doch möglich sein eine Art Bauplan für diese gleichartigen Objekte zu definieren, mit dessen Hilfe man dann die einzelnen Objekte erzeugen kann. Genau das machen die „Klassen“ in der Objektorientierung.
Eine Klasse nennt man daher auch oft den „Bauplan für ein Objekt“ und bei einem Objekt sagt man „Das Objekt hat den Typ der Klasse“ oder „Das Objekt ist einer Instanz der Klasse“.

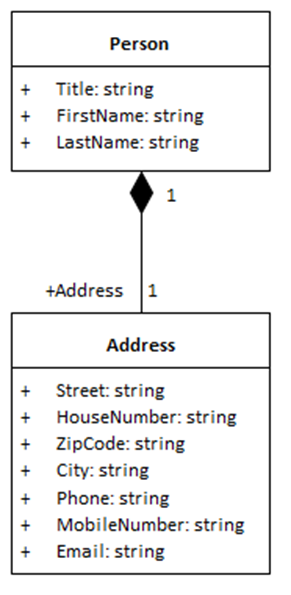
Eine Klasse mit Namen „Person“, die den Type der Objekte aus Abbildung 1 bildet, ist in Abbildung 2 als UML-Element dargestellt. Man sieht im oberen Bereich den Namen der Klasse fett gedruckt und darunter Eigenschaften, die die Klasse datentechnisch genauer definieren. In diesem Fall hat die Klasse zunächst mal drei Eigenschaften
- Title
- FirstName
- LastName
Hinter dem jeweiligen Namen der Eigenschaft steht durch einen Doppelpunkt getrennt ihr Datentyp. In diesem Fall hat jede Eigenschaft den primitiven Datentyp „string“ – die Daten werden also als Zeichenkette gespeichert.
Die beiden Objekte in Abbildung 1 können aus der Klasse Person erzeugt werden. Damit ist festgelegt, welche Eigenschaften die Objekte haben und mit welchen Daten man sie belegen darf.
In der objektorientierten Programmierung hat man das Prinzip von Klassen und Objekten in die zur Verfügung stehenden Konstrukte einer objektorientierten Programmiersprache integriert. Man kann also mit Hilfe von objektorientierten Programmiersprachen Klassen definieren und aus diesen dann Objekte erzeugen.
Mit Hilfe der Programmiersprache C# würde man die Klasse Person wie sie in Abbildung 2 dargestellt ist folgendermaßen programmieren:
public class Person
{
public string Title { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
}Der Quellcode der Klasse besteht, wie man sieht, wenn man sich mit der Sprache C# schon ein wenig auskennt, rein aus der Definition der drei Eigenschaftswerte der Klasse mit Hilfe von Eigenschaftsvariablen (engl. Properties). Wer sich mit objektorientierter Programmierung schon auskennt, fragt sich vielleicht, wo die Methoden geblieben sind. Diese brauchen wir hier jedoch nicht, da wir ja über Datenmodellierung und Datenmodelle reden. Die Klasse Person ist eine Datenmodell-Klasse und enthält deshalb typischerweise ausschließlich Definitionen von Eigenschaftsvariablen!
Mit einer einzelnen Klasse ist es oft nicht getan. Das Beispiel der Person wird auch noch erweitert werden durch zusätzliche weitere Klassen. Auf jeden Fall bilden diese Datenmodell-Klassen dann das Datenmodell für eine Softwareanwendung – hier zum Beispiel einer Adressverwaltung.
Man findet den Begriff des Datenmodells auch in so genannten Entwurfsmustern für objektorientierte Software wieder. Entwurfsmuster sind standardisierte Baupläne für objektorientierte Software, die bestimmte wiederkehrende Probleme lösen und einzelne Klassen in größere Zusammenhänge setzen.
Es gibt zum Beispiel die Entwurfsmuster „Model – View – Controller (MVC)“ und deren Weiterentwicklung „Model – View – ViewModel (MVVM)“ für den Entwurf einer Softwareanwendung mit grafischer Benutzeroberfläche. In beiden Entwurfsmustern steck der Begriff „Model“ drin. Dies meint genau ein Datenmodell, wie es die Klasse Person definiert. Das ich hier von Datenmodellen, anstatt nur von Modellen spreche liegt daran, dass ich es ja auch mit UML-Modellen zu tun habe, die eine andere Art von Modell sind. Um hier Missverständnisse zu vermeiden, hat sich es als hilfreich erwiesen Datenmodell-Klassen auch als „Datenmodelle“ und nicht nur als „Modelle“ zu bezeichnen.
Das Datenmodell wird erweitert
Ich möchte das Datenmodell, welches bislang nur aus einer einzigen Klasse Person besteht, nun erweitern. Am Ende soll das Datenmodell in der Lage sein, Personen mit Adressen für eine Adressverwaltungssoftware abzubilden.
Dazu definieren wir zunächst eine weitere Klasse, die die Adresse einer Person datentechnisch abbildet.

Abbildung 3 zeigt die Klasse Address als UML-Darstellung und der zugehörige Quellcode in C# sieht folgendermaßen aus:
Wie bringt man jetzt die Klasse Person und die Klasse Address in einen Zusammenhang, so dass die Adresse zu einer Person gehört?
public class Address
{
public string Street { get; set; }
public string HouseNumber { get; set; }
public string ZipCode { get; set; }
public string City { get; set; }
public string Phone { get; set; }
public string MobileNumber { get; set; }
public string Email { get; set; }
}Machen wir dies zunächst im UML-Modell, also mit Hilfe grafischer Modellierung. In UML gibt es eine bestimmte Art von Verbindung, mit der man zwei Klassenelemente verbinden kann, die aussagt, dass eine Klasse bzw. deren Objekt ein Unterelement einer anderen Klasse ist. Diese Verbindung nennt man eine Kompositionsbeziehung (engl. Composition). Charakteristisch für diese Verbindung ist die schwarze, ausgefüllte Raute an einem Ende.
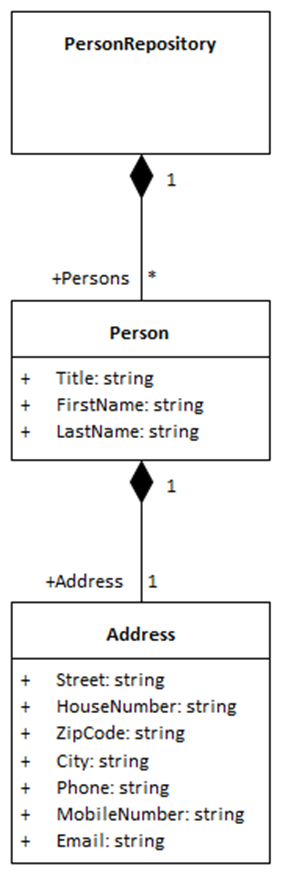
In Abbildung 4 ist das UML-Modell mit der Kompositionsbeziehung zwischen der Klasse Person und der Klasse Address zu sehen. Die schwarze Raute ist immer an dem Element zu sehen, welches enthält. Das bedeutet man muss das Diagramm von der Raute aus lesen als „Person enthält Adresse“.
Was man an der Kompositionsbeziehung noch sieht, sind Zahlen und das Wort „+Address“. Die Zahlen sagen etwas darüber aus, wie oft ein Element in einem anderen enthalten sein soll oder darf. Da in diesem Fall an beiden Enden der Kompositionsbeziehung eine 1 steht, bedeuted dies, wenn man es wieder von der Raute aus liest: „Eine Person enthält eine Adress“.
Um das Wort „+Address“ zu erklären, muss ich kurz ausholen. Die Komposition definiert auch einen Eigenschaftswert für eine Klasse – analog zu den Einträgen im Kasten der Klasse. Nur ist dieser Eigenschaftswert nicht von einem primitiven Datentyp (Zahl, Text, bool), sondern vom Typ einer anderen Klasse, nämlich der wo die Kompositionsbeziehung mit dem Ende ohne Raute endet.
Nun enthält einer Klasse normalerweise keine andere Klasse, sondern ein Objekt dieser anderen Klasse. In der Programmiersprache definiert man ein Objekt als Variable und kann über den Variablennamen dann auf dieses Objekt zugreifen. Diesen Variablennamen muss man natürlich auch definieren. Dies ist genau der Text „+Address“, der definiert, dass es einen Eigenschaftsvariable vom Typ „Address“ (Name der Klasse an der die Komposition endet) und gleichzeitig auch mit Namen „Address“ geben soll (Text an der Kompositionsbeziehung). Das „+“ bedeutet dann noch, dass die Eigenschaft öffentlich sichtbar (public) sein soll.
Die Kompositionsbeziehung mit ihren Zahlen und Namen ist also für eine Eigenschaft eines komplexen Datentype quasi gleichbedeutend mit einer Zeile innerhalb des Kastens der Klasse (UML-Klassenattribut) für eine Eigenschaft mit einem primitiven Datentyp.
Im C#-Quellcode sieht das Ganze dann folgendermaßen aus:
public class Person
{
public string Title { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public Address Address { get; set; }
}In der Klasse Person kommt unten eine Zeile hinzu, die eine weitere Eigenschaftsvariable mit Namen „Address“ und Typ „Address“ definiert. Das hier Name und Typ identisch sind ist möglich und erlaubt, aber möglicherweise am Anfang etwas verwirrend. Es ist aber durchaus übliche Praxis. Man hätte den Namen der Variable aber auch anders wählen können – z.B. „AddressOfPerson“. Dann würde die Codezeile lauten:
public Address AddressOfPerson { get; set; }Zudem müsste man auch den Text im UML-Diagramm an der Komposition entsprechend anpassen.
Mehrere Elemente
In der Datenmodellierung kommt es oft vor, dass man von manchen Eigenschaften nicht nur ein Element bzw. Objekt, sondern eine Sammlung bzw. eine Liste braucht. Wenn man das Datenmodell nun so erweitern möchte, dass man zum Beispiel im Rahmen einer Adressverwaltungssoftware viele Personen mit ihren Adressen speichern will, dann braucht man so etwas wie die Möglichkeit eine Sammlung von Objekten zu speichern.
In den Programmiersprachen gibt es dazu entsprechende Möglichkeiten. Die einfachste sind Feldvariablen (eng. Arrays). Noch komfortabler sind verkettete Listen als Datenstruktur einer Elementsammlung.
In der UML-Datenmodellierung werden Sammlungen relativ einfach dadurch ausgedrückt, dass man an dem Ende einer Kompositionsbeziehung wo keine Raute ist, einfach nicht die Anzahl 1 sondern stattdessen „*“ oder „0..*“ angibt. Der Stern steht dabei als Platzhalter für „0 oder mehr“.
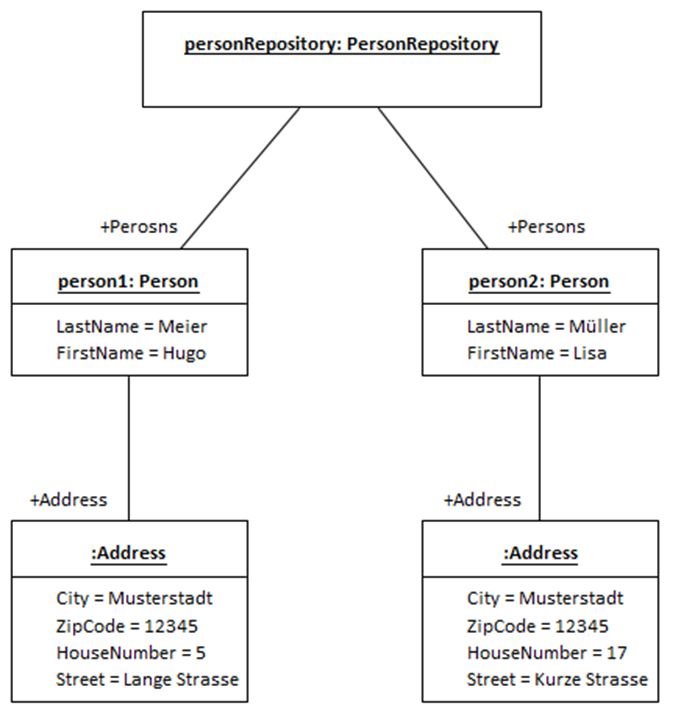
Um dies zu veranschaulichen, erweitere ich das Datenmodell nun um eine weitere Klasse mit Namen „PersonRepository“. Diese Klasse soll eine Liste von Person-Objekten als Eigenschaftsvariable enthalten. Damit wird es möglich, mehrere Person-Objekte als Unterelemente eines PersonRepository-Objektes zu speichern.
In Abbildung 5 ist das erweitere UML-Modell zu sehen. Die Klasse PersonRepository hat selbst keine Eigenschaftswerte mit einem primitiven Datentyp. Daher ist im Kasten der Klasse außer dem Namen nichts zu sehen. Die Komposition zur Klasse Person hat als Definition der Anzahl einen Stern. Das bedeutet, sie enthält oder kann eine Sammlung bzw. Liste von Person-Objekten enthalten. Die Sammlung ist wiederum eine Eigenschaftsvariable mit dem Namen Persons.
Der Code dazu sieht so aus:
public class PersonRepository
{
public List<Person> Persons { get; set; }
}Da es sich um eine Liste handelt, die mehrere Objekte aufnehmen kann, ist der Variablenname in Mehrzahl gewählt. Leider findet man immer wieder UML-Modelle oder sogar Quellcode, wo Namen von Listen oder Sammlungen nicht in Mehrzahl gewählt sind. Ich kann nur dringend dazu raten dies nicht zu tun, da dies die spätere Benutzung unnötig verwirrend macht.
Objekte und Objektmodelle als Instanz des Datenmodells
Nun möchte ich noch zeigen, wie man nun aus diesen Klassen Objekte erzeugen kann und wie sich diese im UML-Modell darstellen.
Der folgende Code erzeugt Objekte des Datenmodells mit Hilfe des new-Operators der Programmiersprache und füllt diese mit ein paar konkreten Daten:
PersonRepository personRepository = new PersonRepository();
personRepository.Persons = new List<Person>();
Person person1 = new Person
{
FirstName = "Hugo",
LastName = "Meier",
Address = new Address
{
Street = "Lange Strasse",
HouseNumber = "5",
ZipCode = "12345",
City = "Musterstadt"
}
};
personRepository.Persons.Add(person1);
Person person2 = new Person
{
FirstName = "Lisa",
LastName = "Müller",
Address = new Address
{
Street = "Kurze Strasse",
HouseNumber = "17",
ZipCode = "12345",
City = "Musterstadt"
}
};
personRepository.Persons.Add(person2);
In UML würde das Ganze in einem Objektdiagramm zum Beispiel folgendermaßen aussehen (Abbildung 6):
Serialisierung
Datenmodelle und ihre Klassen bilden wie oben schon gesagt die Basis einer Softwareanwendung. Alle weiteren Klassen und Komponenten einer Anwendung nutzen diese Datenmodelle als Fundament. Ziel fast jeder Anwendung ist es normalerweise Daten einzulesen, zu verändern und diese ggfs. wieder abzuspeichern.
Bei objektorientiert programmierten Anwendungen ist es immer so, dass alle Daten in Form von Objekten im Arbeitsspeicher vorliegen müssen, um damit zu agieren. Zum Start der Anwendungen werden Daten geladen und Objekte im Arbeitsspeicher erzeugt. Beim Speichern der Daten werden aus diesen Objekten dann wieder persistente Daten in Form von Datenbankeinträgen oder Dateien gemacht.
Glücklicherweise ist es leicht aus Datenmodell-Objekten zum Beispiel Dateien in verschiedenen Formaten zu erzeugen, die diese Objekte 1:1 abbilden. Zwei beliebte Formate die Objekte direkt abbilden sind XML und JSON.
Fast alle Programmiersprachen bieten Bibliotheken an, die aus einem Datenmodellobjekt XML oder JSON erzeugen. Dies nennt man Serialisierung. Den umgekehrten Weg, also von XML oder JSON in ein Objektmodell im Arbeitsspeicher nennt man Deserialisierung.
Was vielen Leuten nicht klar ist, ist, dass man sowohl XML als auch JSON aus dem gleichen Datenmodell heraus erzeugen kann und beide Serialisierungen dann inhaltlich identisch sind (semantische Gleichheit). Durch die Programmierbibliotheken können sowohl XML als auch JSON mit wenigen Zeilen Quellcode erzeugt werden.
Der folgende Quellcode erzeugt aus dem Beispielobjekt einmal XML und einmal JSON.
// create JSON
JsonSerializerOptions options = new JsonSerializerOptions
{
WriteIndented = true,
DefaultIgnoreCondition = JsonIgnoreCondition.WhenWritingNull
};
string jsonString = JsonSerializer.Serialize(personRepository, options);
// create XML
StringWriter stringwriter = new StringWriter();
XmlSerializer serializer = new XmlSerializer(personRepository.GetType());
serializer.Serialize(stringwriter, personRepository);
string xmlString = stringwriter.ToString();
Das erzeugte XML und JSON sieht folgendermaßen aus:
{
"Persons": [
{
"FirstName": "Hugo",
"LastName": "Meier",
"Address": {
"Street": "Lange Strasse",
"HouseNumber": "5",
"ZipCode": "12345",
"City": "Musterstadt"
}
},
{
"FirstName": "Lisa",
"LastName": "M\u00FCller",
"Address": {
"Street": "Kurze Strasse",
"HouseNumber": "17",
"ZipCode": "12345",
"City": "Musterstadt"
}
}
]
}<?xml version="1.0" encoding="utf-16"?>
<PersonRepository xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Persons>
<Person>
<FirstName>Hugo</FirstName>
<LastName>Meier</LastName>
<Address>
<Street>Lange Strasse</Street>
<HouseNumber>5</HouseNumber>
<ZipCode>12345</ZipCode>
<City>Musterstadt</City>
</Address>
</Person>
<Person>
<FirstName>Lisa</FirstName>
<LastName>Müller</LastName>
<Address>
<Street>Kurze Strasse</Street>
<HouseNumber>17</HouseNumber>
<ZipCode>12345</ZipCode>
<City>Musterstadt</City>
</Address>
</Person>
</Persons>
</PersonRepository>Man sieht also wie einfach es ist mit Hilfe eines Datenmodells XML oder JSON aus einem Objektmodell zu erzeugen oder dies zu verarbeiten.
Zusammenfassung
Mir war es wichtig hier einmal zu zeigen, dass Datenmodelle in Quellcode und Datenmodellierung mit Hilfe von UML äquivalente Ansätze sind. Aus einem UML-Klassenmodell kann man gut Datenmodell-Code erzeugen, genauso gelingt dies auch umgekehrt, also vom Code zu UML. Dies liegt daran, dass beide Definitionen den gleichen Grad an Abstraktion haben und dieselben Inhalte beschreiben können.
In der Datenmodellierung geht es immer darum, dass Klassen als Baupläne für Objekte Dinge aus der realen Welt abbilden. Damit kann eine objektorientierte Software dann arbeiten.
Datenmodellobjekte lassen sich durch XML- oder JSON-Serialisierung einfach laden und speichern und man kann mit wenig Aufwand schnell eine lauffähige Software auf die Beine stellen.
Bei der Modellierung mit UML-Klassendiagrammen sollte man beachten, dass man primitive Eigenschaftswerte als Klassenattribute in den Kasten der Klasse modelliert (als UML-Attribute) und komplexe Eigenschaftswerte über Kompositionsbeziehungen abbildet, auch wenn dies auch anders ginge. Zudem sollte man die Eigenschaftsnamen so wählen, dass Listen einen Namen in Mehrzahl und einzelne Objekte einen Namen in Einzahl bekommen.
Zwei Aspekte in der Datenmodellierung habe ich in diesem Beitrag noch nicht behandelt: Vererbung und „Referenzieren von Objekten statt Komposition“. Dies werde ich versuchen in einem separaten Beitrag einmal noch näher zu beschreiben.
Ich hoffe, ich konnte mit dem Beitrag dazu beitragen das Verständnis für Datenmodelle und Datenmodellierung zu verbessern. Viel Erfolg bei der Entwicklung von Datenmodellen.
3 Kommentare zu „Datenmodelle in Code und Datenmodellierung mit UML“