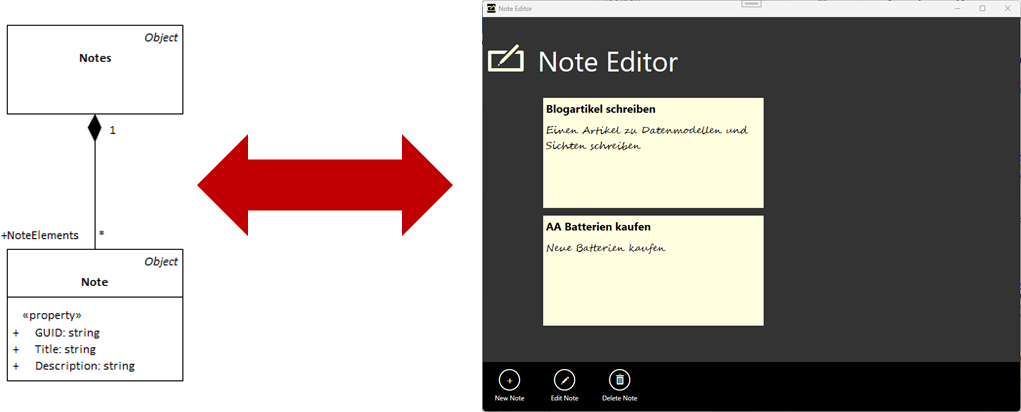
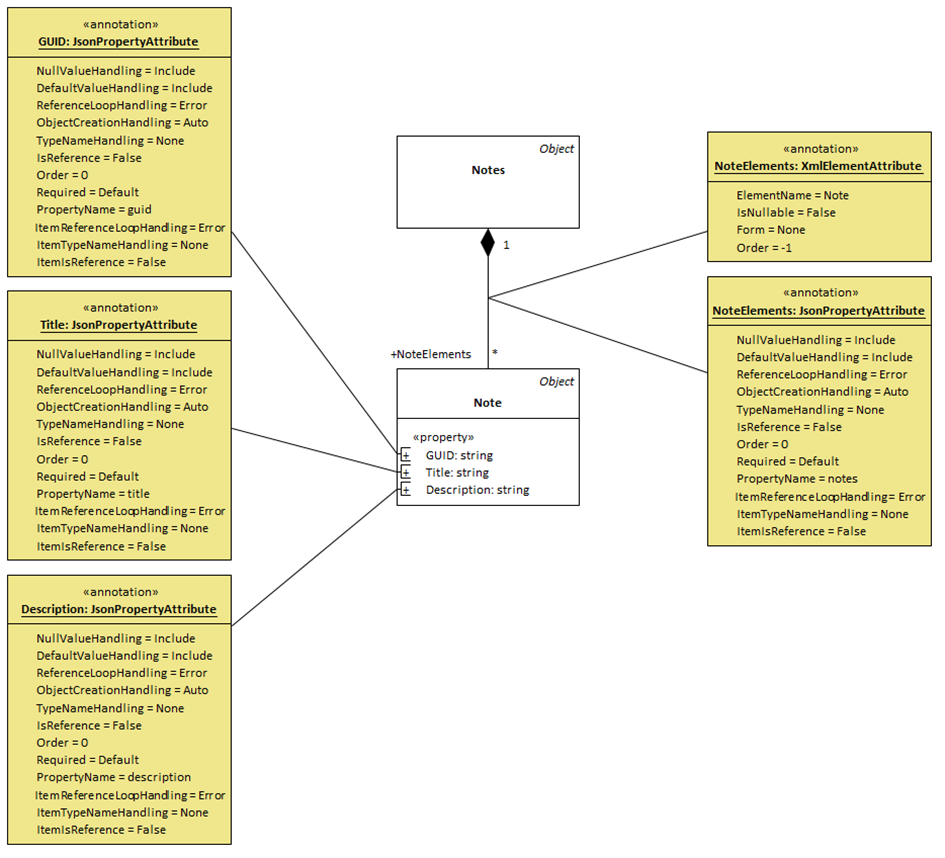
Was ist QVT?
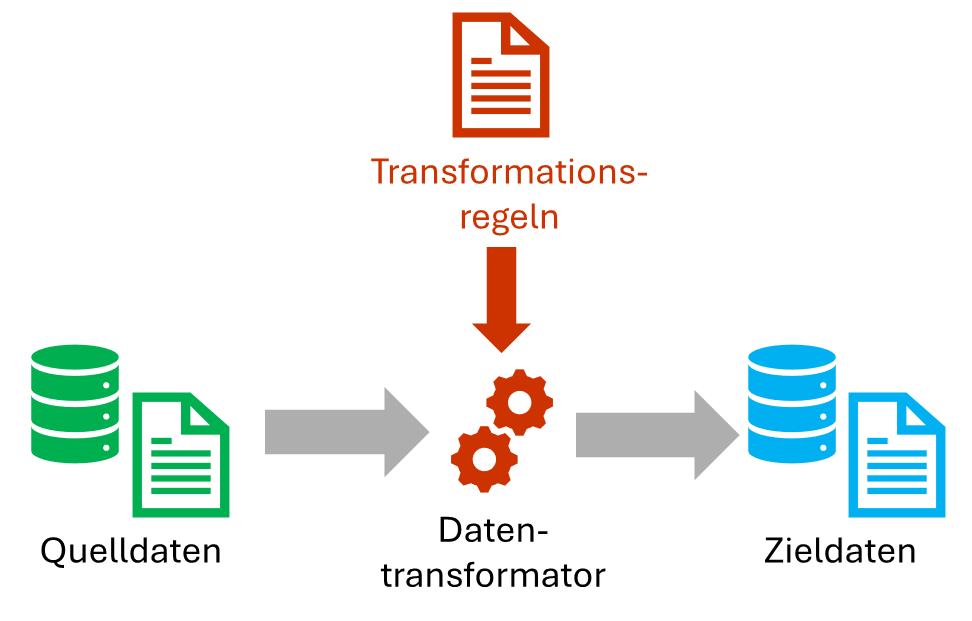
Wenn ich zum Beispiel in Gesprächen auf Tagungen andere Leute mal gefragt habe, ob sie schon mal etwas von QVT gehört haben, kam manchmal die Rückfrage „Ist das nicht dieser Fernsehsender?“. Nein, das wäre QVC! Wenn Sie mehr erfahren wollen was hinter QVT und Daten- und Modelltransformation steckt, dann schauen Sie mal in den Blog-Betrag rein.