Eine moderne, modulare Software besteht eigentlich immer aus mehreren Teilen, die miteinander interagieren. Eine gute Softwarearchitektur benutzt dabei ein so genanntes Schichtenmodell, wie man es auch von Netzwerken her kennt. Dort werden die verschiedenen Netzwerkschichten im so genannten OSI/ISO-Modell voneinander getrennt, damit unterschiedliche Aspekte des Netzwerks getrennt voneinander betrachtet werden können. Ziel ist es eine Modularisierung zu erreichen sowie die Komplexität zu verringern, damit man das Gesamtsystem Netzwerk besser überblicken kann.
Schichtenarchitektur in der Softwareentwicklung
Auch in der Softwarearchitektur kann man die Prinzipien der Schichtenarchitektur verwenden. Bestimmte Softwarekomponenten werden dabei einer bestimmten Schicht zugeordnet, so dass man direkt sehen kann, welche Rolle im Gesamtsystem eine Softwarekomponente spielt und welche Funktionalität man von ihr erwarten kann.
Ein entscheidendes Grundprinzip einer Schichtenarchitektur ist, dass eine Schicht, die höher liegt als eine andere, über eine tieferliegende Schicht Bescheid weiß. Eine untere Schicht weiß jedoch nichts von der oder den Darüberliegenden.
In der Softwarearchitektur bedeutet dies, dass eine Softwarekomponente einer höherliegenden Schicht Abhängigkeiten zu Komponenten einer tiefer liegenden Schicht haben darf, aber niemals umgekehrt!
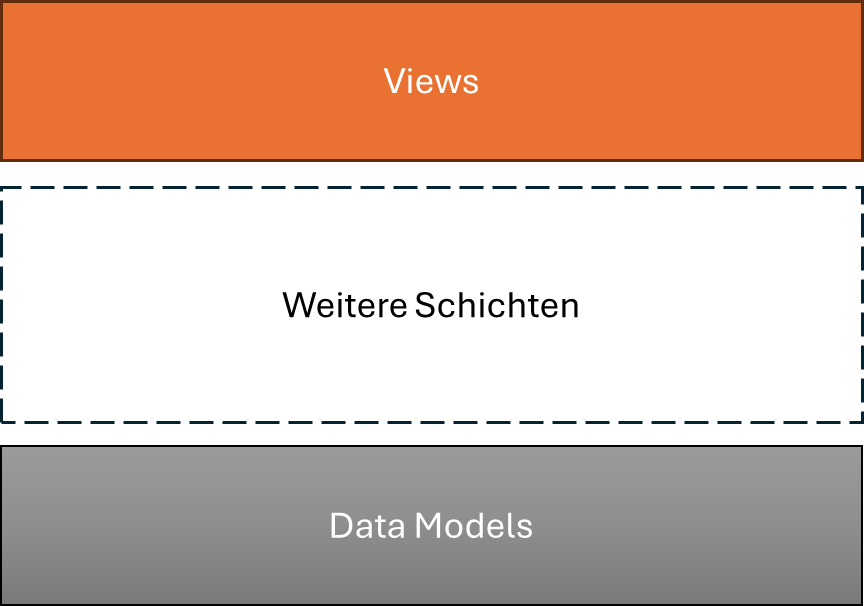
In Abbildung 1 sind zwei Schichten der Softwarearchitektur dargestellt, die Datenmodelle (engl. Data Models) und die Sichten (engl. Views). Die Softwarekomponenten, die ein Datenmodell oder eine Sicht umsetzen werden in diese Schichten thematisch einsortiert.
Zwischen den Datenmodellen und den Sichten existieren noch eine Reihe weiterer Schichten, die aber in diesem Beitrag bewusst noch nicht beschrieben werden sollen. Wichtig ist aber, dass die Datenmodell-Schicht die unterste Schicht und die Sichten normalerweise die oberste Schicht in der Softwarearchitektur darstellt.
Beispiel: Notizverwaltung
Als Beispiel soll eine Notizverwaltung dienen. Die Software soll Daten von Notizen digital speichern und dem Benutzer anzeigen, bzw. zur Bearbeitung anbieten. Typischerweise werden Daten in Softwareanwendungen entweder neu erstellt, gelesen, bearbeitet oder gelöscht. Man bezeichnet dies in der Softwareentwicklung auch mit der Abkürzung CRUD, was für Create, Read, Update und Delete steht. So gut wie alle Funktionen einer Software lassen sich auf dieses Schema abbilden.
Das Datenmodell der Notizverwaltung
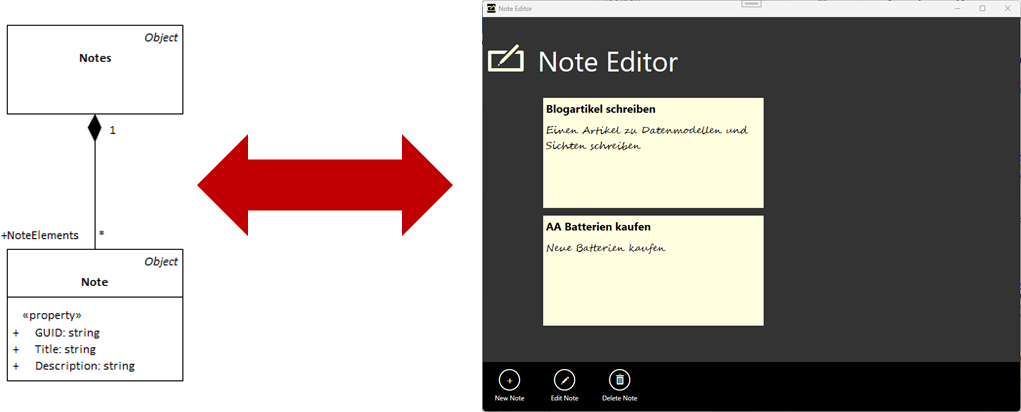
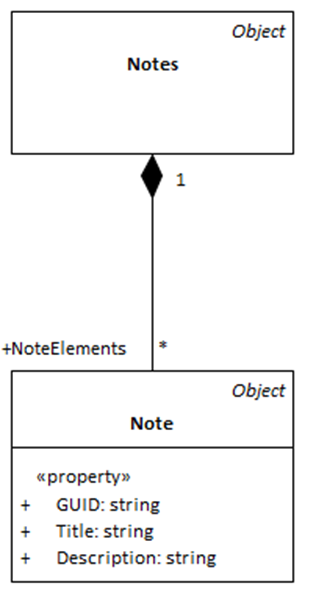
Abbildung 2 zeigt das Datenmodell der Notizverwaltung in UML-Darstellung. Dieses Modell wird 1:1 im Code umgesetzt und als Softwarekomponente in die Schicht „Data Models“ eingeordnet. Eine ausführliche Beschreibung, wie man Datenmodelle mit UML und C# erstellt, ist im Artikel Datenmodelle in Code und Datenmodellierung mit UML beschrieben.
Objekte der Daten
Mit Hilfe dieses Datenmodells lassen sich nun Datenobjekte bilden. In Abbildung 3 sind Beispieldaten von 2 Notizen als UML-Objektmodell zu sehen. Dieses UML-Modell mit seiner Darstellung der Objekte mit Hilfe des Objektdiagramms ist bereits eine Visualisierung von Daten und damit bereits auch eine Sicht auf die Daten.
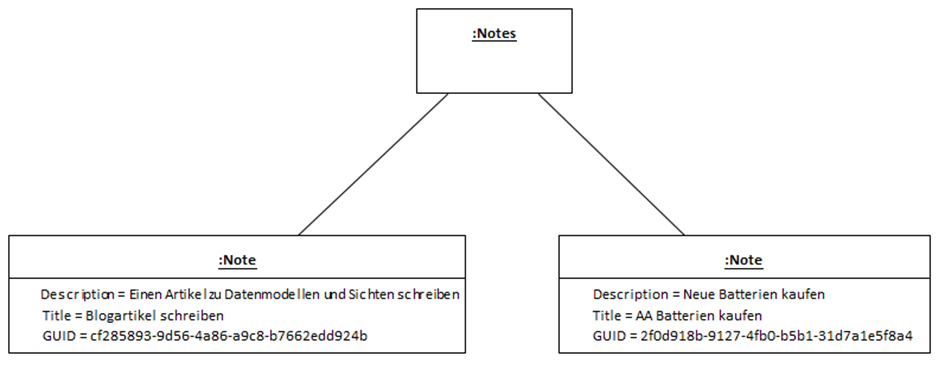
Eine solche Sicht ist für eine Zielgruppe interessant, die an einer eher fachlich-technischen Darstellung von Objektdaten interessiert ist. Dies sind beispielsweise Softwareentwickler oder Sie als Leser dieses Artikels.
Grafische Benutzeroberflächen sind Sichten
Andere Sichten auf die Daten, die als Zielgruppe zum Beispiel keine IT-Spezialisten haben, brauchen daher eine benutzerfreundlichere – vielleicht könnte man auch sagen Laienhaftere – Sicht auf die Objektdaten, z.B. in Form von grafischen Benutzeroberflächen.
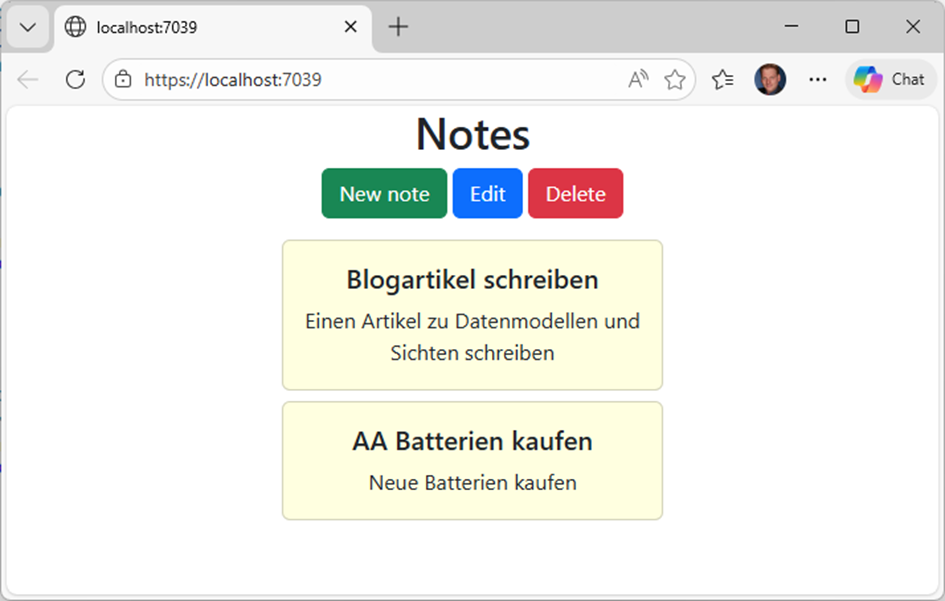
In Abbildung 4 ist eine Sicht in Form einer Web-Applikation realisiert. Die Daten der Notizen erscheinen hier als gelbe Notizzettel und der Titel der Notiz wurde durch Fettdruck hervorgehoben.
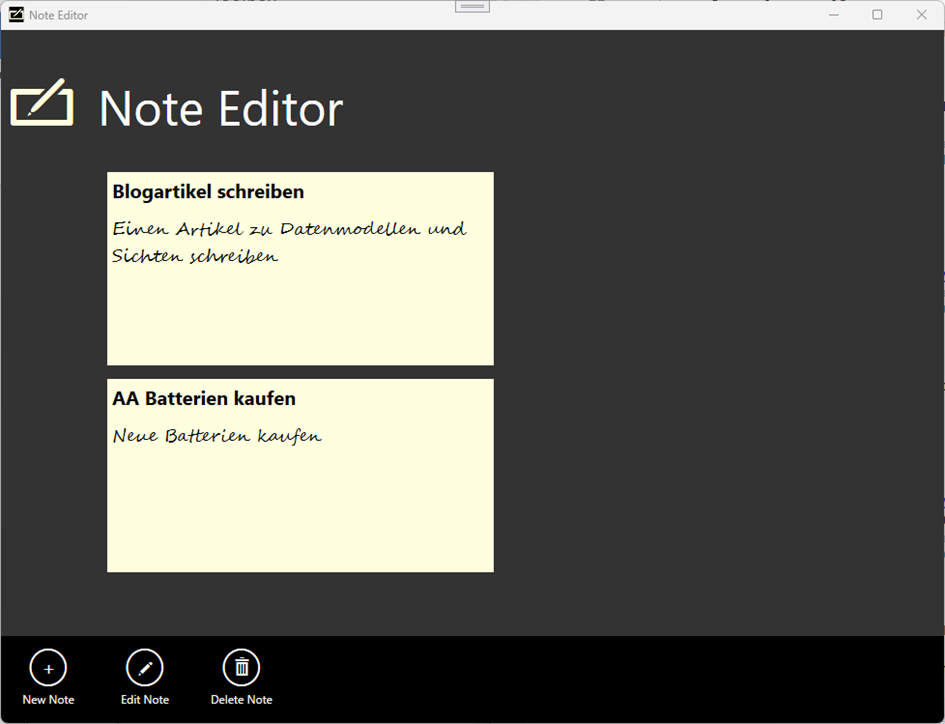
Eine alternative an Windows 8 Apps angelehnte Benutzeroberfläche ist in Abbildung 5 zu sehen. Auch hier wird dasselbe Datenmodell und dieselben Daten verwendet, um die Sicht mit den notwendigen Daten zu versorgen. Die Sicht sieht jedoch wieder anders aus.
Tabellen-Sichten
Eine weitere Art eine Sicht auf die Daten zu bilden kann die Darstellung als Tabelle sein. Abbildung 6 zeigt die beiden Datenobjekte als Tabellendarstellung (hier in Excel). Die oberste Zeile enthält die Titel der Eigenschaften und darunter befinden sich die eigentlichen Daten. Jede Zeile entspricht dabei einem Objekt.
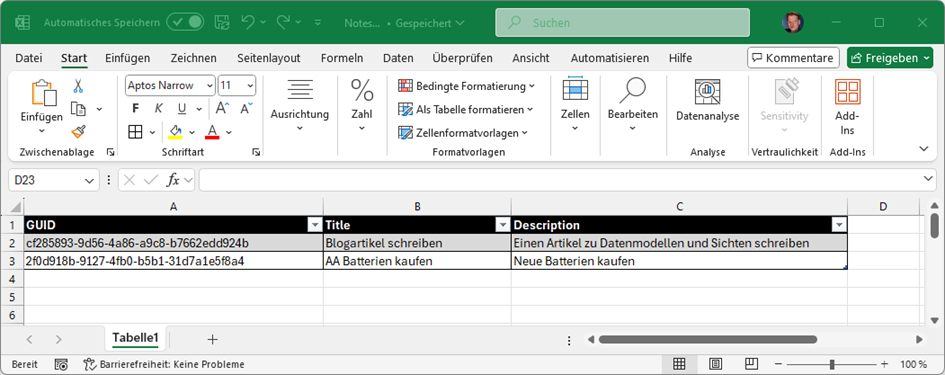
Daten in Tabellenform darzustellen ist ein sehr übliches Verfahren in der elektronischen Datenverarbeitung. In relationalen Datenbanksystemen mit SQL (RDBMS) ist das sogar die einzige Art der Datenspeicherung. Wer schon einmal versucht hat ein komplexeres Objektdatenmodell in einer Tabellenkalkulationssoftware zu speichern, stößt spätestens dann an eine Grenze, wenn es darum geht ein mehrdimensionales Objektmodell in eine zweidimensionale Tabelle abzubilden. Daher haben Datenbanksysteme auch oftmals eine Sammlung von Tabellen mit Relationen dazwischen und man muss schauen, dass man Objektmodelle möglichst geschickt auf die Tabellen abbildet – und umgekehrt.
Wichtig zu merken ist aber, dass eine Tabelle normalerweise einer Sammlung von gleichartigen (zu einer Klasse gehörenden) Objekten entspricht und eine Zeile in der Tabelle einem konkreten Objekt in Form seiner Daten.
Serialisierungen
Auch textuelle Formate, die in der Lage sind, Objekte und ihre Daten darzustellen, sind im Prinzip spezielle Sichten auf die Daten. Am häufigsten trifft man in der Praxis heute auf JSON- oder XML-Serialisierungen. Solche Darstellungen sind – wie auch UML eher etwas für Spezialisten. Noch dazu können JSON- oder XML-Datensichten auch für den Datenaustausch zwischen Maschinen genutzt werden (Machine-To-Machine-Communication, M2M). Man trifft sie daher auch oft als Übertragungsformate in Web-APIs/Microservices oder als Speicherformate an.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "notes": [ { "guid": "cf285893-9d56-4a86-a9c8-b7662edd924b", "title": "Blogartikel schreiben", "description": "Einen Artikel zu Datenmodellen und Sichten schreiben" }, { "guid": "2f0d918b-9127-4fb0-b5b1-31d7a1e5f8a4", "title": "AA Batterien kaufen", "description": "Neue Batterien kaufen" } ] } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<?xml version="1.0" encoding="utf-16"?> <Notes xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <Note> <GUID>cf285893-9d56-4a86-a9c8-b7662edd924b</GUID> <Title>Blogartikel schreiben</Title> <Description>Einen Artikel zu Datenmodellen und Sichten schreiben</Description> </Note> <Note> <GUID>2f0d918b-9127-4fb0-b5b1-31d7a1e5f8a4</GUID> <Title>AA Batterien kaufen</Title> <Description>Neue Batterien kaufen</Description> </Note> </Notes> |
Zusammenfassung
Daten, die im Speicher eines Rechners verarbeitet werden, müssen oftmals für verschiedene Benutzergruppen sichtbar gemacht werden. Diese Aufgabe hat die Sicht (engl. View). Sie stellt zum Beispiel durch eine grafische Benutzeroberfläche Daten so aufbereitet dar, dass ein Benutzer diese Daten leicht einsehen und bearbeiten kann.
Trennt man die Datenmodelle in der Softwarearchitektur komplett von den Sichten, lassen sich die unterschiedlichsten Sichten auf die Daten parallel realisieren, ohne dass am Datenmodell eine Änderung notwendig wird.
Auch technische Sichten wie UML-Darstellungen oder JSON-, bzw. XML-Serialisierung sind im Prinzip spezielle Daten-Sichten, die für spezielle Benutzer oder die Maschinenkommunikation und den Datentransfer heute essenziell sind.
Wichtig war es mir zu zeigen, dass dieselben Daten ganz unterschiedlich präsentiert werden können, es am Ende aber immer – egal wie die Sicht darauf aussieht – darum geht Datenobjekte, basierend auf Datenmodellen zu zeigen oder zu bearbeiten.