Nach über 10 Jahren praktischer Anwendung der Systemmodellierungssprache SysML, zwei Büchern rund um das Thema SysML und der Schulung von vermutlich über 1.000 Personen möchte ich in diesem etwas längeren Beitrag eine kleine auch vielleicht etwas kritische Bilanz ziehen und gleichzeitig eine Alternative vorstellen, auf die ich vor etwas mehr als einem Jahr gestoßen bin, und die meiner Ansicht nach das Potential hat, Systemmodellierung ohne großen Lern- und Schulungsaufwand für jeden einfach nutzbar und zugänglich zu machen: Die Fundamental Modeling Concepts.
Einleitung: Architekturmodellierung
Ein wesentlicher Teil eines Systemmodells bildet die Beschreibung der Architektur bzw. der Systemstruktur. Die Architektur beschreibt dabei Komponenten, deren Schnittstellen und welche Komponente Daten oder Material mit einer anderen Komponente austauscht. Gleichzeitig gibt es in der Architekturmodellierung auch immer eine Darstellung der Systemzerlegung (Systemdekomposition), so dass ersichtlich wird, welche Komponente Teil einer anderen Komponente ist.
Ein Architekturmodell gibt somit Antworten auf folgende Fragen:
- Aus welchen Komponenten besteht mein System?
- Wie stehen diese Komponenten hierarchisch zueinander? (Wer ist Unterkomponente von wem?)
- Welche Schnittstellen haben die Komponenten um Daten oder Material untereinander auszutauschen und zu verarbeiten?
- Wer tauscht mit wem Daten oder Material über Schnittstellen aus?
- Ist eine Schnittstelle einer Komponente Ausgang, Eingang oder beides (Richtung der Schnittstelle)?
Die Systems Modeling Language (SysML) bietet verschiedene Modellelemente an, um solche Architekturmodelle aufzubauen. Da die SysML auf der Softwaremodellierungssparche UML (Unified Modeling Language) basiert und die UML dazu geschaffen wurde in erster Linie objektorientierte Software zu beschreiben, finden sich einige grundlegende Konzepte davon auch in SysML wieder. Insbesondere das Konzept von Klassen und Instanz findet sich auch in SysML, allerdings unter leicht abgewandelten Begriffen. Komponenten in SysML werden dabei durch so genannte Blöcke definiert. Die Blöcke entsprechen weitegehend den Klassen in UML, werden aber umbenannt. Wohl um auch Anwender ohne Hintergrund der Softwaretechnik einen einfachen Zugang zu gewähren.
Instanzen von Blöcken bilden dann die so genannten Property-Elemente. Mit Hilfe von Block- und Property-Elementen können nun Systemstrukturen (Komponenten) modelliert und grafisch dargestellt werden.
Zur Darstellung von Schnittstellen kennt die SysML das Element des Port, der grafisch als kleines Element auf der Kante einer Komponente dargestellt wird. In SysML ist hier durch einen Pfeil im inneren meist auch die Richtung der Schnittstelle vorgegeben.
Um eine Komponente modellieren zu können ist es gemäß SysML-Spezifikation zunächst notwendig Blöcke und die Daten- oder Materialtypen für die Ports zu definieren. Dies geschieht zumeist in einer zentralen Typenbibliothek im Modell.
Hat man diese Datentypen definiert, kann man darauf basierend mit der eigentlichen Systemmodellierung beginnen.
Einstiegshürden
Mehrere Möglichkeiten im Standard
SysML ist ein Standard, der an verschiedenen Stellen mehrere prinzipielle Möglichkeiten bietet, um ein Modellierungsproblem zu lösen. Hintergrund dabei ist vermutlich, dass sich bei der Standardisierung viele Parteien auf einen gemeinsamen Nenner einigen mussten. Jeder möchte dabei natürlich am liebsten das im Standard wiederfinden, was er oder sie bereits kennt oder schon einsetzt. Daher ist ein solcher Standard oftmals auch ein Kompromiss.
Ich selbst habe während meiner Zeit beim Automobilzulieferer Continental SysML maßgeblich als Systembeschreibungssprache etabliert und auch geschult. Dabei würde früh ersichtlich, dass es wenig Sinn macht die komplette SysML zu schulen und anzuwenden, sondern dass man sich auf eine praktikable Teilmenge beschränken sollte, die alle praxisrelevanten Modellierungsaufgaben unterstützt und leicht zu erlernen ist.
Weiterhin haben die wenigsten Kollegen im Umfeld wo mechatronische Systeme entwickelt werden Hintergrundwissen in der Softwaretechnik. Dies fand ich nicht nur bei Continental sondern auch bei den Schulungsteilnehmern immer wieder, die ich in meiner Zeit als Trainer und Consultant bei LieberLieber in modellbasierter Systementwicklung geschult habe. Auf die Frage wer denn die Konzepte der Objektorientierung kenne, meldeten sich zumeist nur 10-20% der Schulungsteilnehmer.
Man kann also nicht davon ausgehen, dass Konzepte wie Klasse und Instanz sowie die damit verbundenen Darstellungen der UML oder objektorientierter Programmiersprachen als bekannt vorausgesetzt werden können.
Dies führte zu einem pragmatischen Ansatz in der Form, dass ich bei SysML beispielsweise Blöcke nie direkt in Architekturdarstellungen verwende, sondern immer nur deren Instanz (Property-Elemente). Die Verwirrung ist nämlich erst mal sehr groß wenn man sich mit den Konzepten nicht auskennt und dann gesagt bekommt, man solle in manchen Fällen Blöcke, in anderen aber Instanzen von Böcken zur Darstellung von Systemkomponenten verwenden. Zudem sind die Beispiele im SysML-Standard in diesem Punkt auch nicht eindeutig.
Letztendlich wurden aus der Menge der SysML-Elemente nur genau 3 ausgewählt, um Architekturdarstellungen zu machen:
- Property-Elemente als Instanzen von Blöcken für die Darstellung der Komponenten
- Flow Ports zur Darstellung der Schnittstellen
- Ein Item-Flow-Konnektor als durchgezogene Linie zwischen verbundenen Flow Ports
Das folgende Bild zeigt ein Beispiel eines mit SysML erstellten Architekturmodells:

Viele Elemente zur Typdefinition
In SysML gibt es verschiedene Elemente um Schnittstellen zu definieren. Damit kann man also festlegen welche Art von Daten oder Material aus einer Schnittstelle herauskommen oder hineinfließen. SysML kennt dabei mehrere Elemente um so etwas zu spezifizieren.
- Quantity Kinds
- Units
- Flow Specifications
- Data Types
Sie dürfen sich gerne im SysML Standard genauer anschauen, was diese Elemente alles bedeuten und für was diese nutzbar sind. Auf jeden Fall gab es mit diesen Typ-Elementen in der praktischen Anwendung – ob in den Schulungsbeispielen oder später – immer die meisten Fragen und Fehler. Zu allem Überfluss wurden diese Elemente in den verschiedenen Versionen des SysML-Standards auch gerne mal verändert, was dazu führt, dass einmal gelerntes wieder neu erlernt werden muss oder man sich entscheiden muss die Änderungen einfach nicht mitzugehen und bei der aktuellen Version der SysML zu bleiben.
Lücken in der SysML
Bereits kurz nach dem Aufbau der ersten Systemmodelle fiel auf, dass manche Aspekte, die man gerne im Modell wiedergefunden hätte im SysML Standard so nicht vorgesehen sind. Der wichtigste Punkt war dabei die Tatsache, dass SysML nun eine Art von Komponente kennt und man nicht unterscheidet zwischen Software-, Elektronik- oder Mechanikkomponenten.
Der Ansatz zur Lösung dieses Problems war, die SysML zu erweitern und solche spezifischen Komponenten einzuführen. Glücklicherweise ist die SysML als erweiterbare Sprache definiert. Somit lassen sich auch solche Lücken einfach füllen. Allerdings ist es dann eine angepasste SysML, die in anderen Modellen so nicht zum Einsatz kommt.
Werkzeughürden aufgrund verstreuter Daten
Eine große Schwierigkeit stellte und stellt für die Anwender auch die Tatsache dar, dass die Daten aufgrund der SysML-Spracharchitektur in den Modellierungswerkzeugen in verschiedenen Teilen verstreut abgelegt werden. SysML ist als so genanntes UML-Profil definiert. Profil wird der Erweiterungsmechanismus der UML genannt, mit dem man aus UML neue Sprachen ableiten kann. Die Nutzung von Profilen führt dazu dass die Anwender an mindestens zwei verschiedenen Stellen im Werkzeug Daten editieren müssen, um die gewünschten Einstellungen für die Modellelemente zu erreichen: In den Elementeigenschaften und in den sogenannten „Tagged Values“. Wer sich nie mit dem Thema UML-Profile näher beschäftigt hat, für den erschließt sich zunächst auch nicht, warum man einmal hier etwas einstellt, andere Dinge aber dort.
Dieses Problem sollte man nicht unterschätzen, da auch nicht alle Modellnutzer täglich mit dem Modellierungswerkzeug arbeiten und dann nach einiger Zeit auch oftmals nicht mehr wissen, wo nochmal genau eine Eigenschaft geändert werden muss. Dies führt dann zu Frustration und im schlimmsten Fall dazu, dass die Modelle gar nicht oder nur noch äußerst ungern weiter genutzt werden.
Doppelpunkte in Namen
Einige Elemente in SysML-Architekturmodellen sind Instanzen. Eine Instanz wird durch einen Text beschrieben, der aus dem Namen des Elements und dem Namen des klassifizierenden Elements (Blockname) besteht. Beide Begriffe werden dabei durch einen Doppelpunkt getrennt. Heisst der Block beispielsweise „Temperatursensor“, so heisst eine Instanz davon zum Beispiel „TS1 :Temperatursensor“, wobei „TS1“ hier der Name der Instanz ist. Diese Art der Darstellung ist auch nicht selbsterklärend und für viele Anwender verwirrend. Dies zeigt sich auch, wenn Anwender während einer Übung in einer SysML-Schulung gebeten werden zunächst auf dem Flipchart oder Whiteboard ein Modell hinzuzeichnen. So gut wie Niemand zeichnet auch die Doppelpunkte hin, obwohl dies vorher erklärt worden ist.
Für die Praxis ist es für den großen Teil der Anwender wichtig zu sehen, welche Art von Schnittstelle hier genutzt wird. Dafür genügt zum Verständnis auch eine einfache Darstellung ohne Instanzname und Doppelpunkt.
Fundamental Modeling Concepts
Auf die so genannten Fundamental Modeling Concepts (FMC) wurde ich aufmerksam durch ein Gespräch, das ich auf dem Tag des Systems Engineering (TdSE) 2016 mit Dr. Oskar von Dungern während einer Kaffeepause führte.
Er erzählte mir, dass er eine Initative für ein Datenformat zum Austausch von Systemspezifikationen ins Leben gerufen habe, dass es auf einfache Art und Weise ermögliche komplette Systemspezifikationen, bestehend aus Anforderungen, Architektur und Verhaltensbeschreibungen auszutauschen und aus verschiedenen Quellen zu integrieren: SpecIF (Specification Integration Facility). Als Beschreibungssprache für Architekturen benutze er dabei die Fundamental Modeling Concepts.
Meine Neugierde war geweckt. Nicht nur an SpecIF, sondern auch an FMC. Ich wollte mir das ganze mal näher anschauen, auch im Hinblick darauf, wie sich das evtl. mit SysML kombinieren oder vereinbaren lässt.
Bereits auf dem Rückweg schaute ich mir im Zug seinen Beitrag zum TdSE 2016 dazu an. Ich fand es dahingehend sehr interessant, da FMC einiges davon vereinte was ich mit meinem praxisbezogenen Einsatz von SysML auch getan hatte:
- Konzentration auf die wesentlichen, wenige Elemente
- Intuitive Darstellung um den Anlernaufwand gering oder gegen Null zu halten
Im weiteren Verlauf schaute ich mir FMC noch genauer an: Die Grundlagen der Fundamental Modeling Concepts wurden bereits Ende der 1970er Jahre von Prof. Siegfried Wendt entwickelt. Die Weiterentwicklung zum heute bekannten Stand erfolgte dann durch ihn und seine Mitarbeiter in den darauffolgenden Jahren.
Besonders interessant daran finde ich, dass dort Dinge, die in UML und SysML immer wieder wieder zu Problemen führen, bereits analysiert und gelöst worden sind. Leider ist der Ansatz so gut wie kaum bekannt und wurde vorwiegend im Umfeld des Instituts von Prof. Wendt am Hasso Plattner Institut gelehrt und eingesetzt. Eine genaue Beschreibung des gesamten Konzeptes findet sich im Buch Fundamental Modeling Concepts, das 2005 – also bereits 2 Jahre vor dem ersten offiziellen SysML-Standard – bei Wiley erschienen ist.

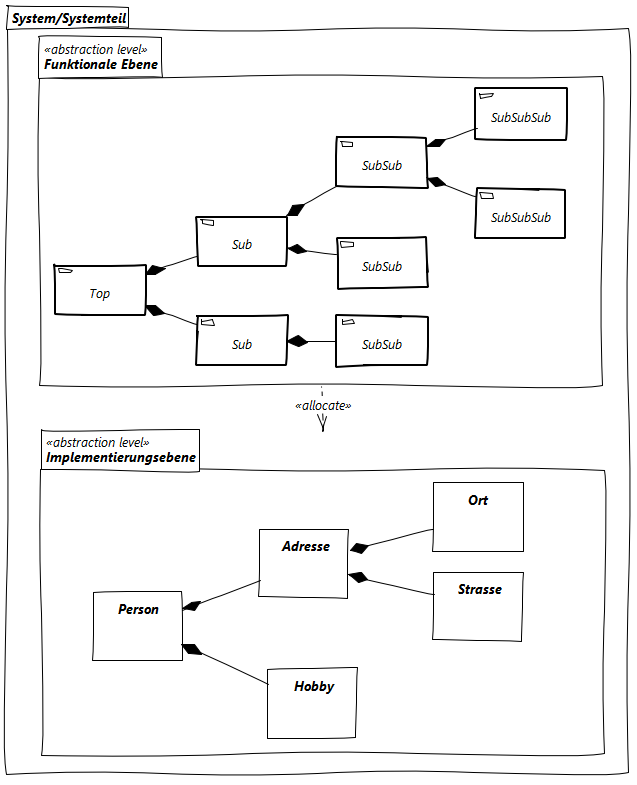
Das was sich mit den SysML-Architekturdiagrammen beschreiben lässt, lässt sich auch mit dem Compositional Structures Diagramm des FMC beschreiben. Grund genug für mich einmal zu untersuchen, ob es nicht möglich ist FMC für das Modellierungswerkzeug Enterprise Architect von Sparx Systems nutzbar zu machen.
In meinem Urlaub Anfang 2017 fand ich etwas Zeit dazu mir darüber Gedanken zu machen und etwas umzusetzen. Entstanden daraus ist ein UML-Profil und ein kleines Plugin für Enterprise Architect, welches FMC für das Systems Engineering mit Enterprise Architect nutzbar macht: FMC4SE.
Fundamental Modeling Concepts for Systems Engineering (FMC4SE)
FMC4SE besteht aus zwei Teilen: Einem MDG-UML-Profil für Enterprise Architect, das es erlaubt FMC Compositional Structure Modelle mit Enterprise Architect zu erstellen und diese so wie von FMC vorgesehen aussehen zu lassen.
Der zweite Teil ist eine Software für Enterprise Architect (Plugin), die es dem Anwender einfacher machen soll FMC Modelle zu erstellen. Dabei werden beispielsweise die Standarddialoge zum Bearbeiten der Elementeigenschaften durch eigene Dialoge ersetzt, die nur die wesentlichen Dinge an einer zentralen Stelle anzeigen. Dadurch entfällt für den Anwender das fehlerträchtige Editieren an mehreren Stellen im Werkzeug.

Leichte Adaption des FMC-Konzepts
An einer Stelle bin ich bei der Umsetzung der FMC-Profils von der in der Literatur beschriebenen Form abgewichen: Bei FMC werden Kommunikationskanäle durch einen Konnektor mit einem Kreis in der Mitte dargestellt. Ich nutze hingegen den Kreis bei Quelle und Ziel des Kommunikationskanals analog zu einem Port in UML oder SysML. Dies ermöglicht es eine Komponente auch aus einem Gesamtsystem herauszuschneiden, ohne die Schnittstellen zu verlieren, das diese nicht nur am Konnektor “hängen”, sondern an der Komponente selbst definiert und mit dieser implizit verbunden sind.

Der im FMC-Standard vorgesehene Kreis zur Darstellung eines Kommunikationskanals wird also praktisch nur verdoppelt. Ansonsten werden die Elemente so wie bei FMC beschrieben umgesetzt.
Modellierungsassistent
Zur Verbesserung der Benutzerfreundlichkeit dient das erstellte Plugin. Hierbei wird ein Modellierungsassistent umgesetzt der es ermöglicht bei Anlegen neuer Elemente bereits alle wesentlichen Daten wie Typ der Komponente, Name, Art der Komponente (Elektronik, Software, Mechanik etc.) und Beschreibung der Komponente auszuwählen bzw. einzugeben. Ein besonderes Augenmerk gilt dabei der Festlegung des Typs. Auch die Umsetzung der FMC4SE nutzt die zur Verfügung gestellten Konzepte von Klasse und Instanz. Allerdings wird dies durch das Plugin für den Anwender vereinfacht.

Der Dialog für die Eigenschaften enthält eine Auto-Vervollständigung die automatisch beim Tippen bereits existierende Komponenten- oder Schnittstellentypen (Type) anzeigt. Wird eine existierende ausgewählt wird diese automatisch zugewiesen. Existiert keine passende, kann der Anwender mit der „+“-Knopf eine neue erzeugen. Diese wird direkt als Klassen- (für Komponenten) oder Interface-Element in eine zentrale Typenbibliothek einsortiert. Ein Hantieren mit verschiedenen, verwirrenden Datentypen wie bei SysML entfällt damit.
Die Zuordnung der Komponentenart (Kind) wird über farbliche Kennzeichnung erreicht. Damit kann man auf den ersten Blick eine Software- von einer Hardwarekomponente unterscheiden.
FMC4SE ist Open Source und kostenlos
Die FMC4SE Technologie und das Plugin für Enterprise Architect stelle ich als Open Source unter der MIT Lizenz auf Github kostenlos zur Verfügung: https://github.com/oalt/fmc4se. Auch ein kleines Beispielmodell für Enterprise Architect findet sich hier.
Einen Installer für Windows mit dem ersten Release gibt es ab sofort hier.
Der Installer Installiert das Plugin vollautomatisch. Die Definition der MDG Technology (.xml-Datei) und das Beispielmodell (.eap-Datei) werden unter C:\ProgramData\MDD4All\FMC4SE installiert. Sie können diese MDG Technology über die entsprechenden Menüs in jedes Enterprise Architect Modell laden und damit die FMC-Unterstützung aktivieren. Die Software lässt sich über die Systemsteuerung komplett wieder deinstallieren. Daher ist es einfach möglich auch FMC4SE nur mal kurz auszuprobieren. Da es sich um ein Enterprise Architect-Plugin handelt sind zur Installation Administratorrechte notwendig, da die Softwarekomponenten eine Windows COM-Registrierung benötigen.

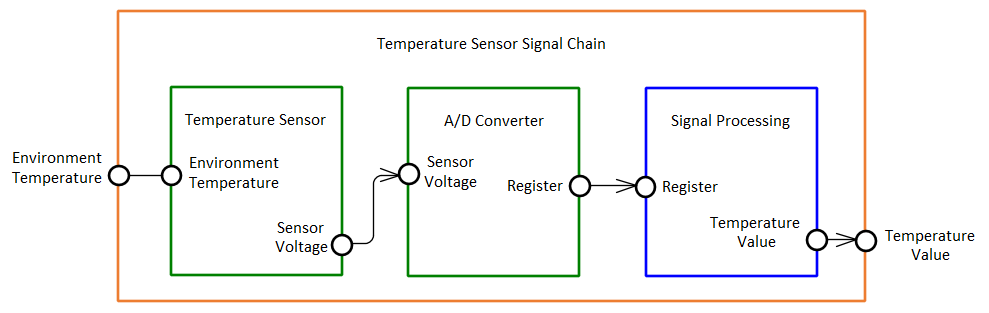
Das im Beispielmodell enthaltene Modell der “Temperatursensorsignalkette” sehen Sie im Bild oben. Auffällig ist die viel weniger überladene Darstellung im Vergleich zu SysML oben. Trotzdem sind meiner Ansicht nach aller wesentlichen, zum Verständnis notwendigen Inhalte vorhanden.
Warum nur FMC Compositional Structures?
FMC definiert neben dem Compositional Structures Diagramm auch noch zwei weitere weitere Diagramme zur Beschreibung von dynamischem Verhalten angelehnt an Petri-Netze und Entity-Relationship-Diagramme zur Beschreibung und Definition von Datenstrukturen.
Diese Diagramme wurden bewusst nicht umgesetzt, da ich persönlich finde, dass hier im Umfeld der UML/SysML mit dem Aktivitätsdiagramm im Bereich dynamische Modellierung und dem Klassendiagramm im Bereich Beschreibung von Datenstrukturen bereits sehr weit etablierte Diagrammarten zur Verfügung stehen, die soweit auch schon bei vielen Anwendern bekannt sind oder bereits angewendet werden. Für mich sind die dazu im FMC-Bereich definierten Notationen weniger intuitiv zugänglich und daher würde ich in von mir verantworteten Modellen immer eine Kombination von FMC Compositional Structures sowie UML/SysML-Klassen- und Aktivitätsdiagrammen vorziehen. Das darf aber jeder gerne halten wie er mag.
Erfahrungswerte
Wie bereits oben erwähnt, habe ich die MDG-Technology und das Plugin bereits Anfang 2017 erstellt. Seit Februar 2017 arbeite ich bei der Firma Polygon – Produktdesign, Konstruktion, Herstellung als Entwickler. Ich setze modellbasierte Entwicklung nicht mehr täglich ein, erstelle jedoch von Zeit zu Zeit ein Modell wenn ich es als hilfreich für meine Arbeit erachte. Für das Modell nutze ich dazu von Beginn an FMC4SE. Meine Kollegen sind größtenteils Maschinenbauingenieure, Designer und Elektroingenieure. Es wurde von meiner Seite her keinerlei Schulung oder Einführung in die Modellnotation durchgeführt, sondern ich habe es einfach genutzt und die Reaktionen beobachtet. Die mit der FMC-Notation erstellten Modelle und Diagramme wurden dabei immer sofort von den Kollegen akzeptiert in Diskussionen und Präsentationen verwendet und verstanden.
Damit kann ich zwar nicht repräsentativ behaupten, dass jeder einen grundsätzlichen intuitiven Zugang zu dieser Modellierungsnotation hat, aber für mein Umfeld kann ich es voll bestätigen. Ich werde daher – bis ich vielleicht noch etwas besseres und intuitiveres finde – die Architekturmodellierung mit FMC4SE und nicht mehr mit SysML-Notation machen. Es ist sehr leicht SysML-Modelle in FMC zu überführen und auch umgekehrt. Daher wäre es jederzeit auch möglich wieder umzusteigen. Ich folge immer meinem Grundsatz “Nur so komplex wie nötig und so einfach wie möglich”. Viel Spaß mit FMC4SE.
Resourcen